Verifying and Validating College ID Images
Akansh Maurya Amith P Sudhanshu Dubey
Mentor Name: Prof. Kavi Arya, Omkar Manjrekar, Andrea F
Duration of Internship: 08/05/2020−27/06/2020
** I cannot share much about the pipeline and procedure because our paper is under review.

Abstract
E-yantra organizes various competitions and MOOCs for students across India. The staff spends a significant amount of time validating ID cards uploaded by eYRC, eYIC and MOOCs participants. Through this project we present an efficient system to verify and validate college ID cards. Our approach is to identify valid college ID cards from a pool of images which may contain other photos too. This is done by a deep image classification model. To extract the textual information from the image we performed text detection and text recognition. We explored different models, evaluated their speed and accuracy for our dataset. Validation of ID card, matching of results of OCR to the ground truth, is done by a custom algorithm which uses partial string matching and fuzzy-set. Also to improve accuracy of our system we have performed some Image processing techniques of which one was to correct the orientation of Image automatically before passing through our classification and OCR model.

Overview of pipeline
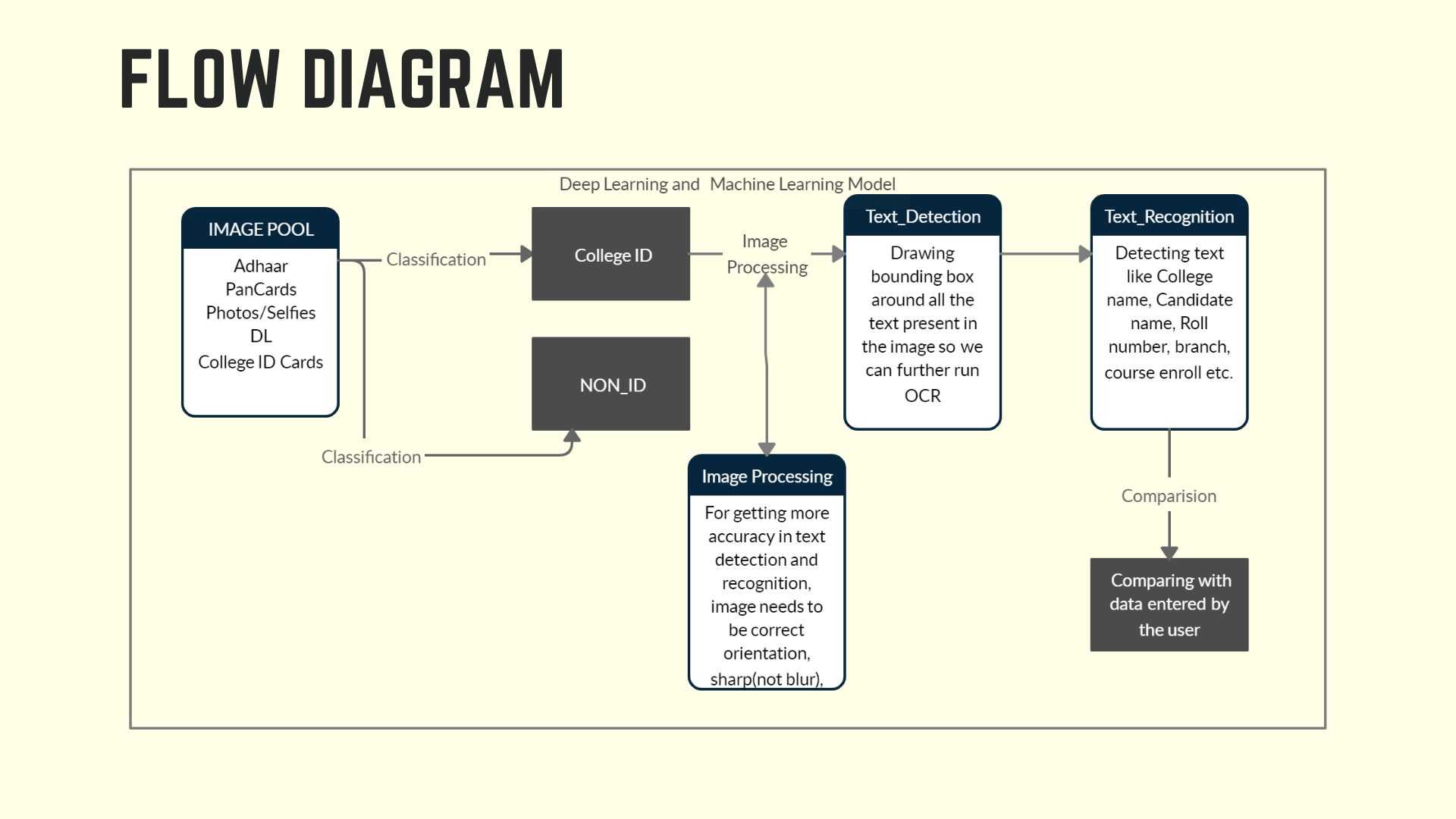
The pipeline for this project consists of four-part. A classification model, that can verify the correct College ID card image from the pool of images. Before passing the Images to the text detection and recognition model, we corrected the image orientation by passing through the Rotate-Net model. The last stage of the pipeline was to match the OCR results from the ground truth to validate an ID card, this was done by the custom algorithm with fuzzy string matching. In the subsequent sections, we have compared different deep learning models, evaluated them on our dataset, and selected the appropriate to achieve maximum efficiency.
Data exploration
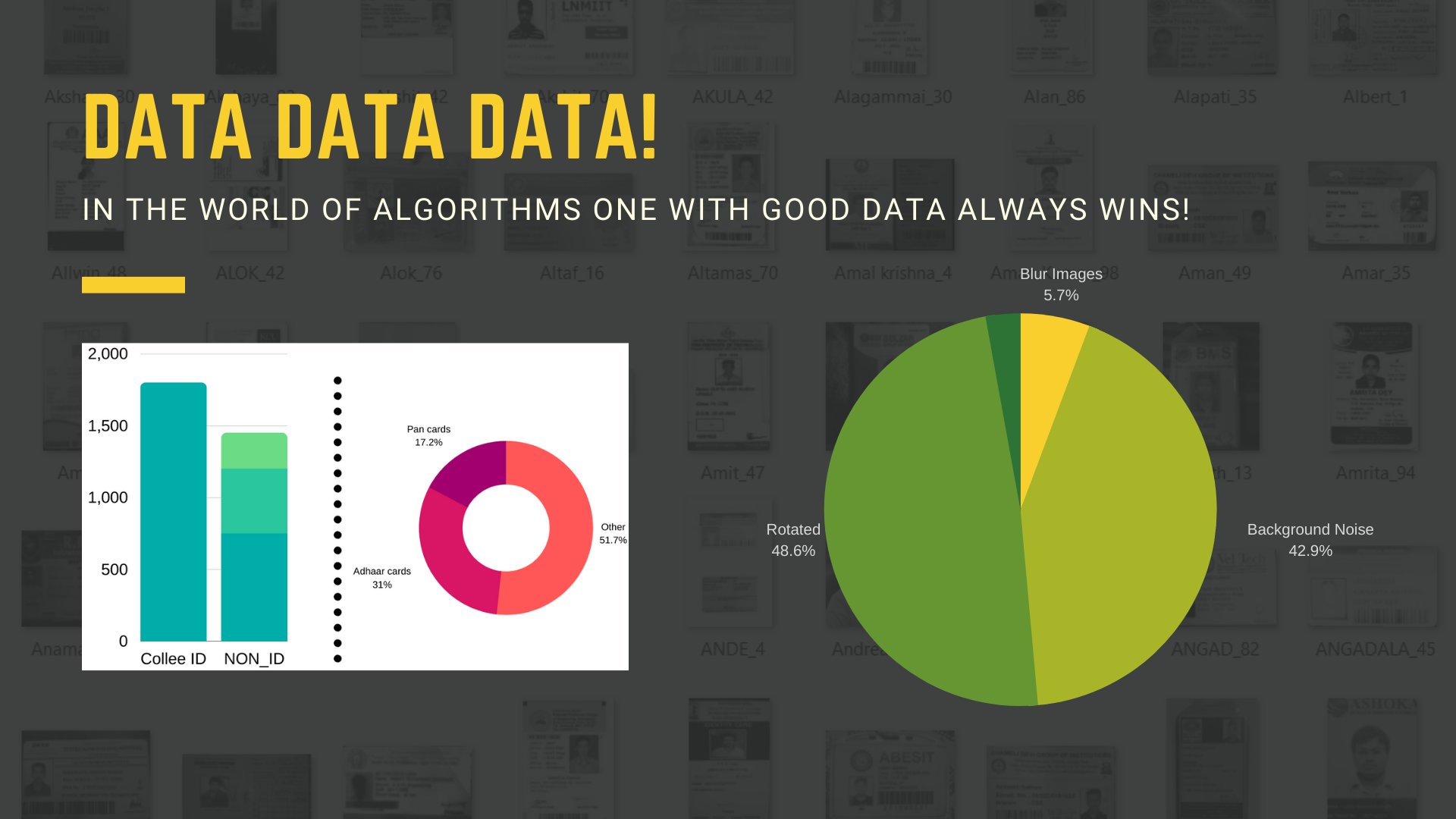
To build the model pipeline and define the problem statement more transparently it was important to introspect the image data we have and measure the variation. As a dataset we started with around 2000 images of which 1800 were valid college ID cards. The rest 200 images consist of aadhaar cards, pan cards, passport size photo and other random images. Most of the images in our dataset were clicked by mobile camera, thus some images were blur, low resolution, presence of background noise and randomly oriented. Many of them were end to end cropped, but it was estimated that only around 2-3 percent of images have background noise. It was estimated that around 8 percent of images were oriented at different angle
Classification Model
Every college has a unique ID card format. Some of the college ID cards were of shape, height ratio
width, 2:5, others were 5:2. Each college ID card was having a different color, different logos, in some
information was typed others were handwritten. This variation of image data made our classification
problem more complex.
However there were few features that humans can identify, every ID card was rectangular in shape, had a
passport size photo of the candidate present inside the ID card, also some textual information like Name,
Roll No., College/University Name was present. Now our task was to segregate these images. On the other
side, non-ID cards have some pattern associated with them, aadhaar cards have a lot of similar features
like the presence of Indian emblem, Indian flag colored strips, QR code, etc. So was the case for PAN
cards.
So we made our classification model with four classes, College ID cards, Aadhaar Cards, PAN cards, and
others. Others include those images which rarely occur in the dataset, mainly selfies, backgrounds, photos
of faces, etc.

Rotate-Net
We have seen that around 10 percent of images in our dataset were in the wrong orientation, specifically for our case they were orientated. ResNet model requires images to be of size 224X224X3. We resized images and also normalized them according to the mean and standard deviation of ImageNet Data set. We trained our model to thirty epochs using Adam optimizer with learning rate of 0.0001 and categorical cross-entropy loss function. With this we got accuracy of 91 percent on our validation set. To improve our accuracy we made few changes in our dataset.Every ID card has a passport size photo of the student. If we try to correct the orientation of faces present in the ID card, eventually we will correct the ID card orientation. So in our dataset we introduced the images of faces available in the open-source data repository. Our hypothesis was that extracting features of faces is easier than the text data present.

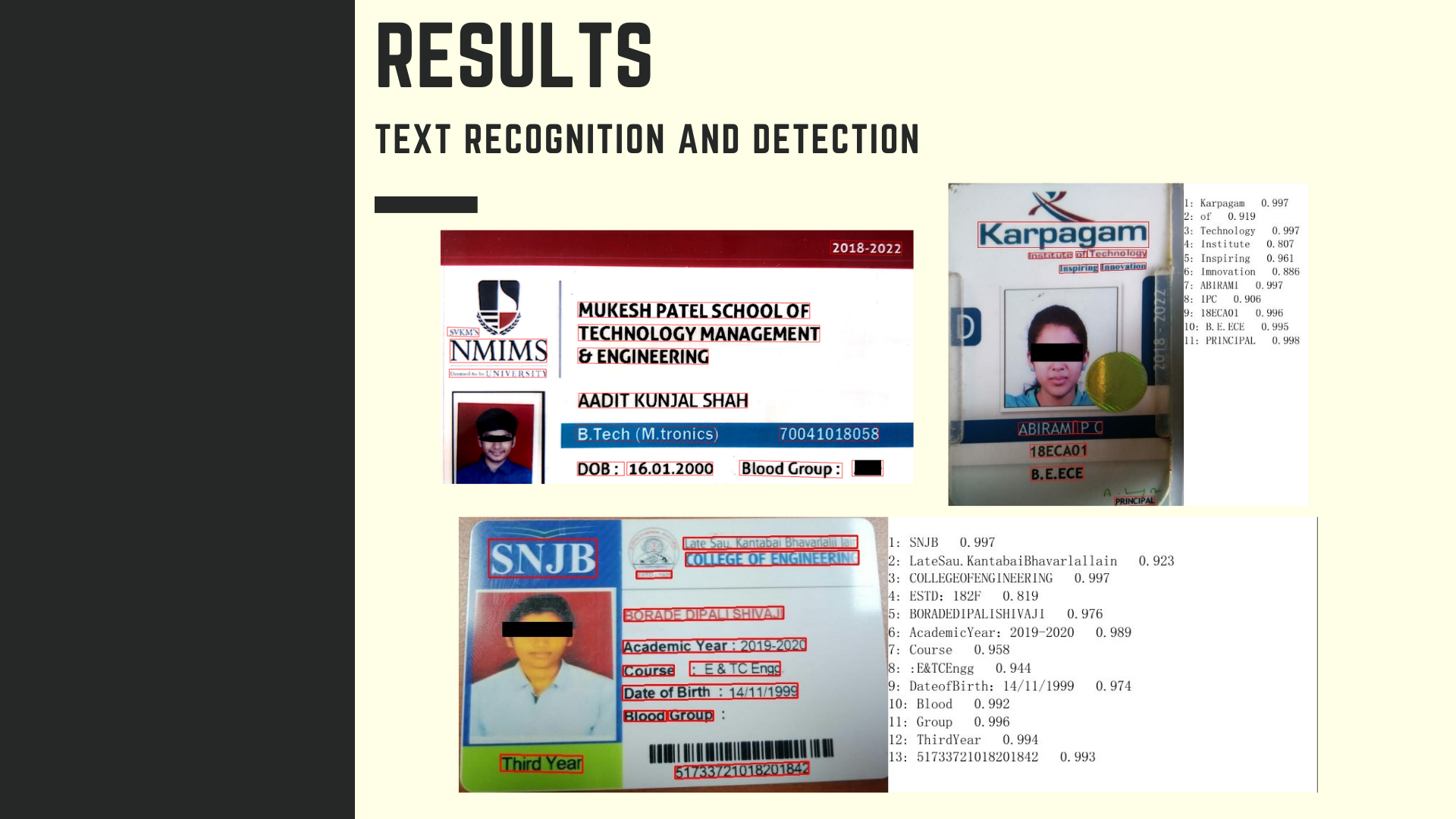
Text detection and Recognition

Results of OCR
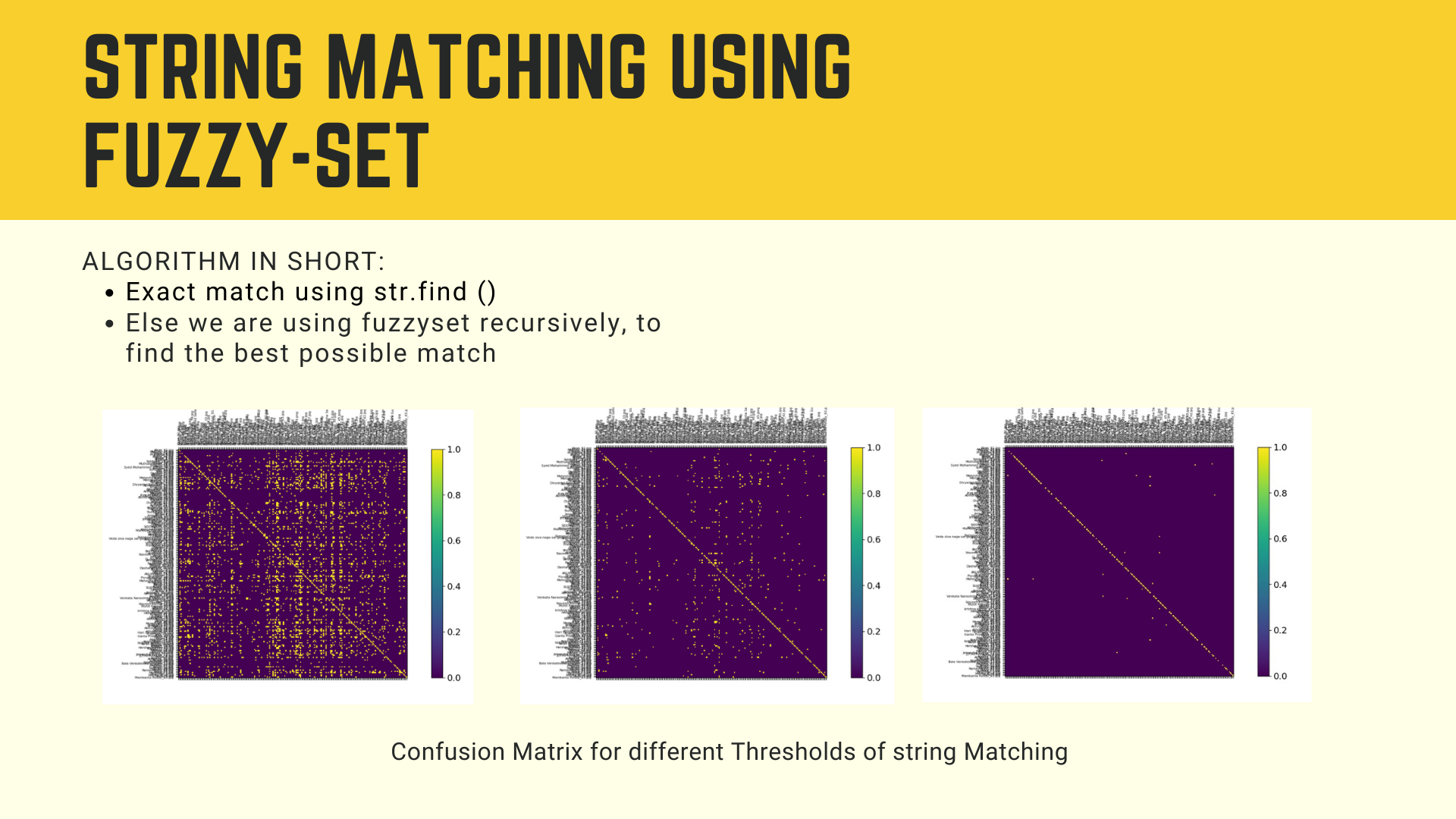
Fuzzy String Matching
The word fuzzy means something that is difficult to understand and explain precisely. In the context of
string matching, fuzzy string matching implies imprecise or approximate string matching. Thus, rather than
a strict true or false, fuzzy string matching would tell how similar are the two given strings.
In this project, we have employed fuzzy string matching to match the text recognised from the ID card to
the information given by students while registering. The reasons for using fuzzy string matching rather
than an exact string matching are as follow:
The text recognition model isn't 100% reliable and so it may make mistakes. An exact string matching
would fail in this scenario, while the fuzzy one would give some score of similarity
- Students may enter information which is logically the same as that on their ID card but is not literally the same. As an example, students often interchange "Engineering" with "Engg." and vice versa. They are not the exact same string but have the same meaning.
- Thus, using fuzzy string matching makes this ID card validation robust and close to the real world.
Credits:
