Fovea Localization for Age-related Macular degeneration (AMD) and Non-AMD Patients
This blog presents the solution to the ADAM challenge hosted by the https://grand-challenge.org. The ADAM challenge focuses on the investigation and development of algorithms associated with the diagnosis of Age-related Macular degeneration (AMD) and segmentation of lesions in fundus photos from AMD patients. In this blog we focus on the subtask of the problem, that is localization of Fovea. The fovea centralis is a small, central pit composed of closely packed cones in the eye. It is located in the center of the macula lutea of the retina.[1] The fovea is responsible for sharp central vision (also called foveal vision), which is necessary in humans for activities for which visual detail is of primary importance, such as reading and driving. The fovea is surrounded by the parafovea belt and the perifovea outer region.[2]

Code can be found here: https://bit.ly/2OZ8uer
More about the competition:
https://amd.grand-challenge.org/Home/
We wil, explore the following:
- Exploratory data analysis
- Data transformation for object detection
- Creating custom datasets
- Creating the model
- Defining the loss, optimizer, and IOU metric
- Training and evaluation of the model
- Deploying the model
Exploratory data analysis
In the dataset, there is a CSV file which has three columns where first column tells the name of the image file, second and third represents x, y coordinate of Fovea’s center. There are 311 Non-AMD patients while 89 are AMD.
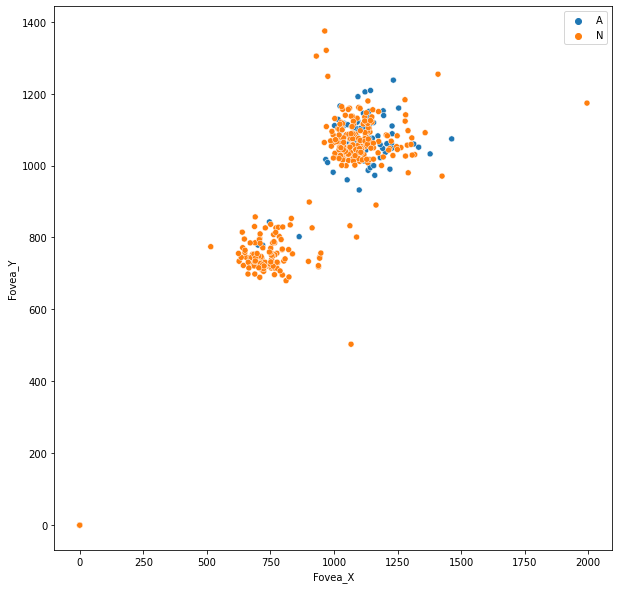
Original size of the image for height varies from 1400 to 2200 and the width ranges from 1400 to 2400 pixels.
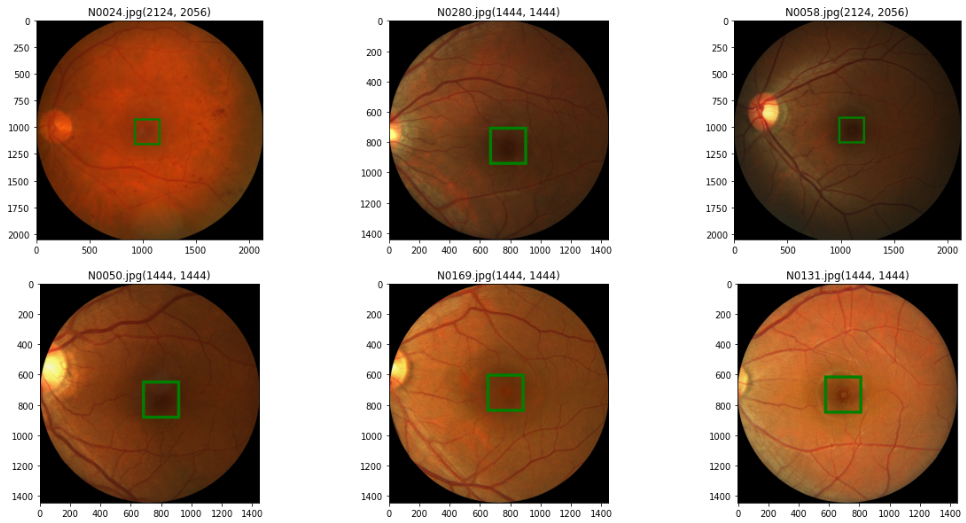
Data Transformation and Augmentation [Results only]
Data augmentation and transformation is a critical step in training deep learning algorithms, especially for small datasets. The iChallenge-AMD dataset in this chapter has only 400 images, which is considered a small dataset. As a reminder, we will later split 20 percent of this dataset for evaluation purposes. Since the images have different sizes, we need to resize all images to a pre-determined size. Then, we can utilize a variety of augmentation techniques, such as horizontal flipping, vertical flipping, and translation, to expand our dataset during training.
-
Image Resizing:
- We will resize the image to (256, 256). We also have to scale the labels in the same ratio. Refer to the code link.
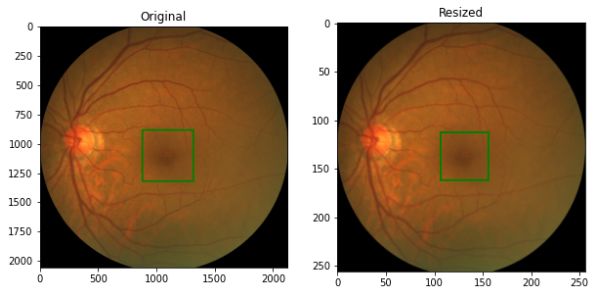
Figure 4: Image Resizing -
Random Vertical Fliping
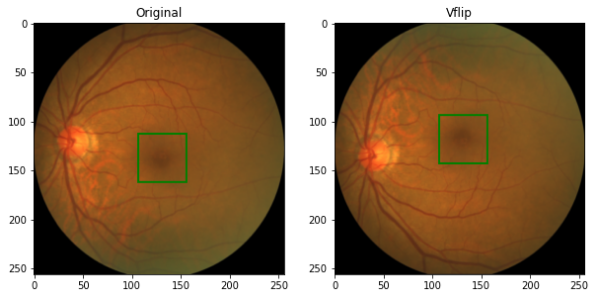
Figure 5: Vertical Flip -
Random Horizontal Fliping
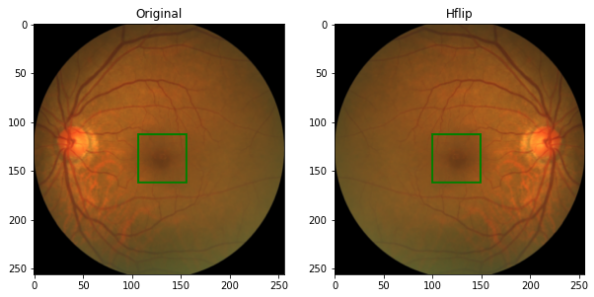
Figure 6: Horizontal Flip -
Random Shifting
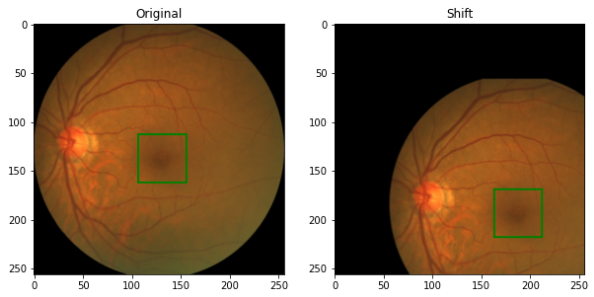
Figure 7: Random Shifting
Creating Model:
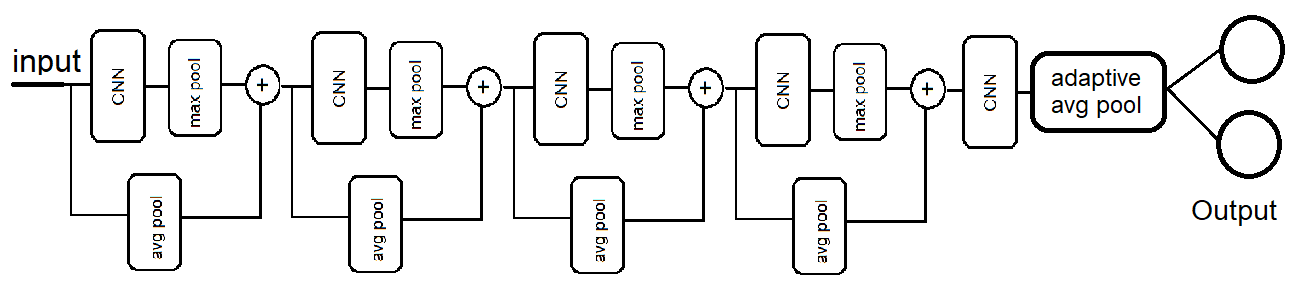
The code snippet shoes the implementation:

The loss, optimizer, and IOU metric:
- Loss Curve
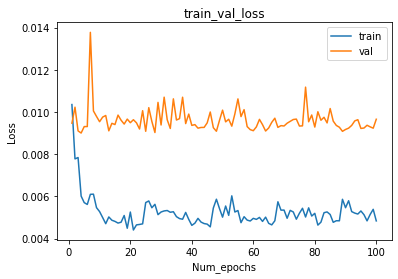
Figure 10: Loss Curve - Accuracy Curve
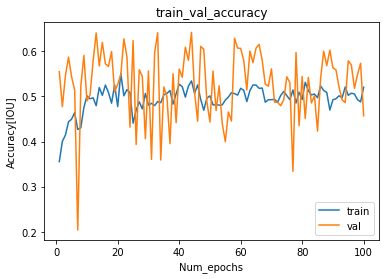
Accuracy Curve - IOU Metric as label in the figure.
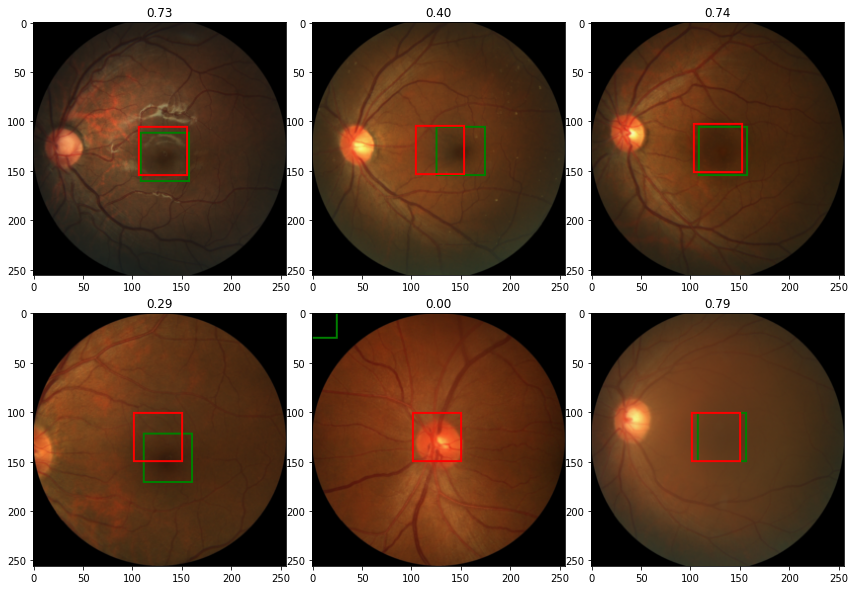
IOU
References:
- https://en.wikipedia.org/wiki/Fovea_centralis
- https://amd.grand-challenge.org/Home/
- https://github.com/akansh12/Computer_vision_Book_solution/blob/main/Michael%20Avendi%20-%20PyTorch%20Computer%20Vision%20Cookbook_%20Over%2070%20recipes%20to%20solve%20computer%20vision%20and%20image%20processing%20problems%20using%20PyTorch%201.x-Packt%20Publishing%20(2020).pdf